Migrating to micro-services: harder than it seems
Common challenges and pitfalls when migrating from monolith to microservices architecture.
Overview
This article explores why microservices adoption has become widespread yet frequently fails to deliver expected benefits. While 63% of enterprises use microservices, only 10% report complete success, with 45% experiencing partial benefits and 8% facing outright failure.
Key Messages for Success
1. Business Alignment Is Critical
Microservices should address specific business needs:
- Agile delivery: Enable rapid feature releases to compete in digital markets
- Scalability: Support independent scaling of components based on demand
Without these drivers, microservices introduce unnecessary complexity.
2. Evaluate If You Actually Need Microservices
Not every organization requires microservices architecture. Google's Istio team discovered their control plane didn't need independent scaling or deployment. Similarly, Botify found that microservices added latency without necessary benefits for their use case.
3. Manage Distributed System Complexity
Microservices create both essential and accidental complexity:
- Essential challenges: Handling partial failures, latency, distributed transactions, and security
- Accidental challenges: Tool proliferation, team upskilling, vendor lock-in concerns
As one architect noted: "distributed systems have higher latency with interprocess communication, creating strong coupling while maintaining monolith disadvantages."
4. Avoid Common Anti-Patterns
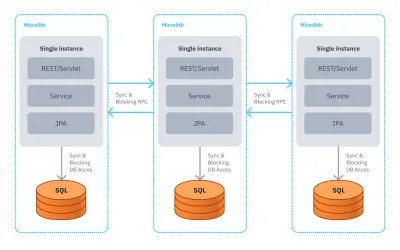
The Distributed Monolith anti-pattern occurs when breaking monoliths into tightly-coupled services. This produces "the complexity of distributed systems, the disadvantages of monoliths — and little to show in exchange."
5. Follow Proven Practices
Digital leaders use:
- Strangler pattern: Progressively extract microservices while maintaining the legacy system
- Event-driven architecture: Minimize coupling through asynchronous communication
- Observability: Implement comprehensive monitoring and tracing
- DevOps platforms: Automate deployment, scaling, and operations
Solution
CodeNOW's DevOps Value Stream Delivery Platform helps teams implement cloud-native best practices, reducing accidental complexity while enabling focus on business outcomes rather than infrastructure concerns.
Written by CodeNOW


